Infrastructure for production AI systems
QYRA Labs builds observability, control, and security infrastructure for modern AI systems — from AI gateways and agent orchestration to governance and MCP security.
AI Security
Security architecture for AI systems interacting with tools, APIs, databases, and MCP servers.
AI Observability
Visibility into agent workflows, orchestration, provider usage, and operational behavior in production AI systems.
AI Governance
Governance, traceability, access control, and operational reliability for production AI deployments.
Products
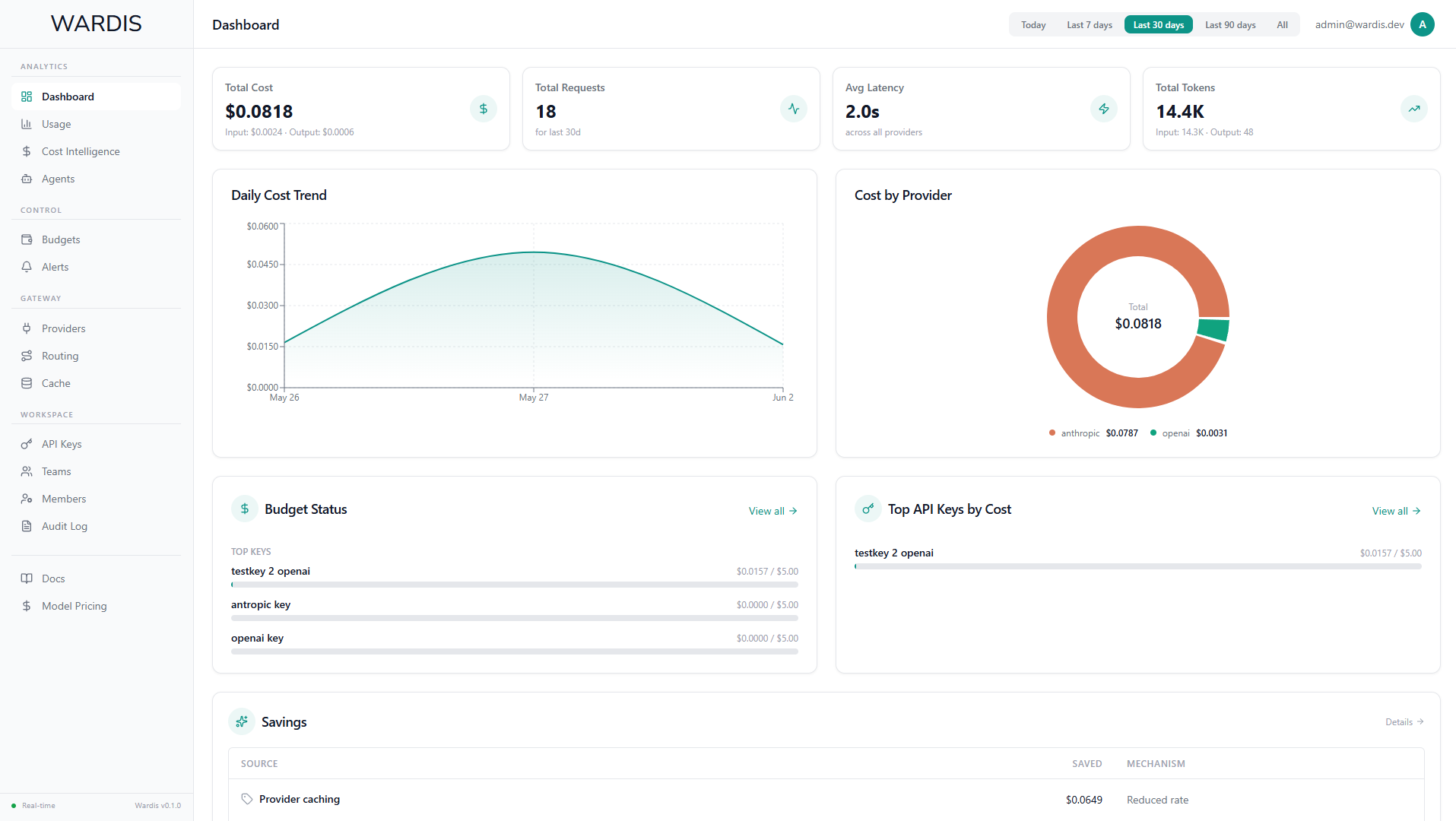
Wardis
AI observability and control platform for modern agentic systems.
Observe, trace, and control AI workflows across models, tools, MCP servers, providers, and multi-agent orchestration environments.
MCP Firewall Beta
Security infrastructure for MCP servers. Detects and blocks prompt injection, jailbreaks, tool hijacking and data exfiltration before they reach your systems.
Built for production environments where AI agents interact with databases, file systems and external APIs.

Why production AI systems require dedicated infrastructure
Traditional infrastructure and monitoring tools were not designed for probabilistic systems. AI agents introduce failure modes that firewalls and WAFs cannot address.
When an AI agent connects to your database, file system or API through MCP, it operates with real credentials and real access. A successful prompt injection doesn't just return wrong answers — it can exfiltrate data, modify records or trigger actions the user never intended.
The attack surface is fundamentally different. Threats arrive as natural language, embedded in seemingly legitimate requests. They exploit the gap between what an instruction says and what it means. Pattern matching alone cannot solve this.
Jailbreaks, context manipulation, tool hijacking, indirect injection through retrieved content — these are not theoretical risks. They are documented, reproducible and increasingly automated.
QYRA Labs builds infrastructure specifically for this problem space. Not wrappers. Not plugins. Dedicated security layers designed from first principles for the unique characteristics of AI agent communication.
Problem-first
Architecture follows constraints, not trends. Every design decision traces back to a specific threat model and documented attack vector.
Production-tested
Built for real operational environments with real traffic. Validated against a broad range of documented attack patterns and realistic workloads.
Transparent
Full audit trails with integrity verification. Explainable decisions. No black boxes where security is concerned.
Human-in-the-loop
Sensitive operations require explicit approval. Automated detection with human oversight for critical decisions.
Contact
For access to MCP Firewall, research collaboration, or technical inquiries.